*五、Spark-local模式*
\1. 上传并安装Anaconda3-2021.05-Linux-x86_64.sh文件
1 | cd /export/server/ |
\2. 过程显示:
1 | ... |
\3. 安装完成后,重新启动

看到base就表示安装完成了
\4. 创建虚拟环境pyspark基于python3.8
1 | conda create -n pyspark python=3.8 |
\5. 切换到虚拟环境内
1 | conda activate pyspark |

\6. 在虚拟环境内安装包
1 | pip install pyhive pyspark jieba -i https://pypi.tuna.tsinghua.edu.cn/simple |
\7. 上传并解压spark-3.2.0-bin-hadoop3.2.tgz
1 | cd /export/server |
\8. 创建软连接
1 | ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/spark |
\9. 添加环境变量
1 | vim /etc/profile |
SPARK_HOME: 表示Spark安装路径在哪里
PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
JAVA_HOME: 告知Spark Java在哪里
HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
HADOOP_HOME: 告知Spark Hadoop安装在哪里
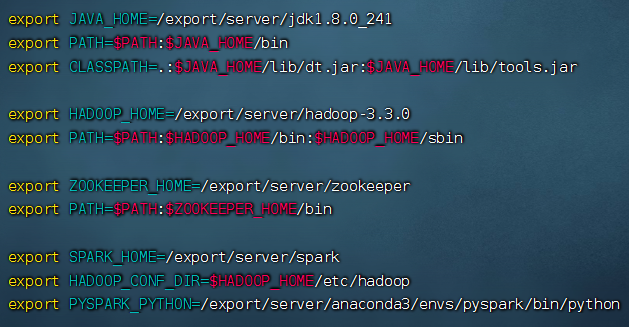
1 | vim .bashrc |
内容添加进去:
1 | #JAVA_HOME |
\10. 重新加载环境变量
1 | source /etc/profile |
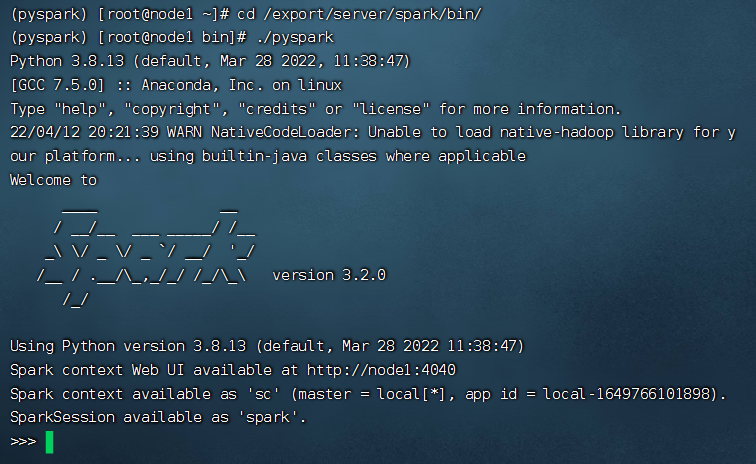
\11. 开启spark
1 | cd /export/server/anaconda3/ens/pyspark/bin/ |
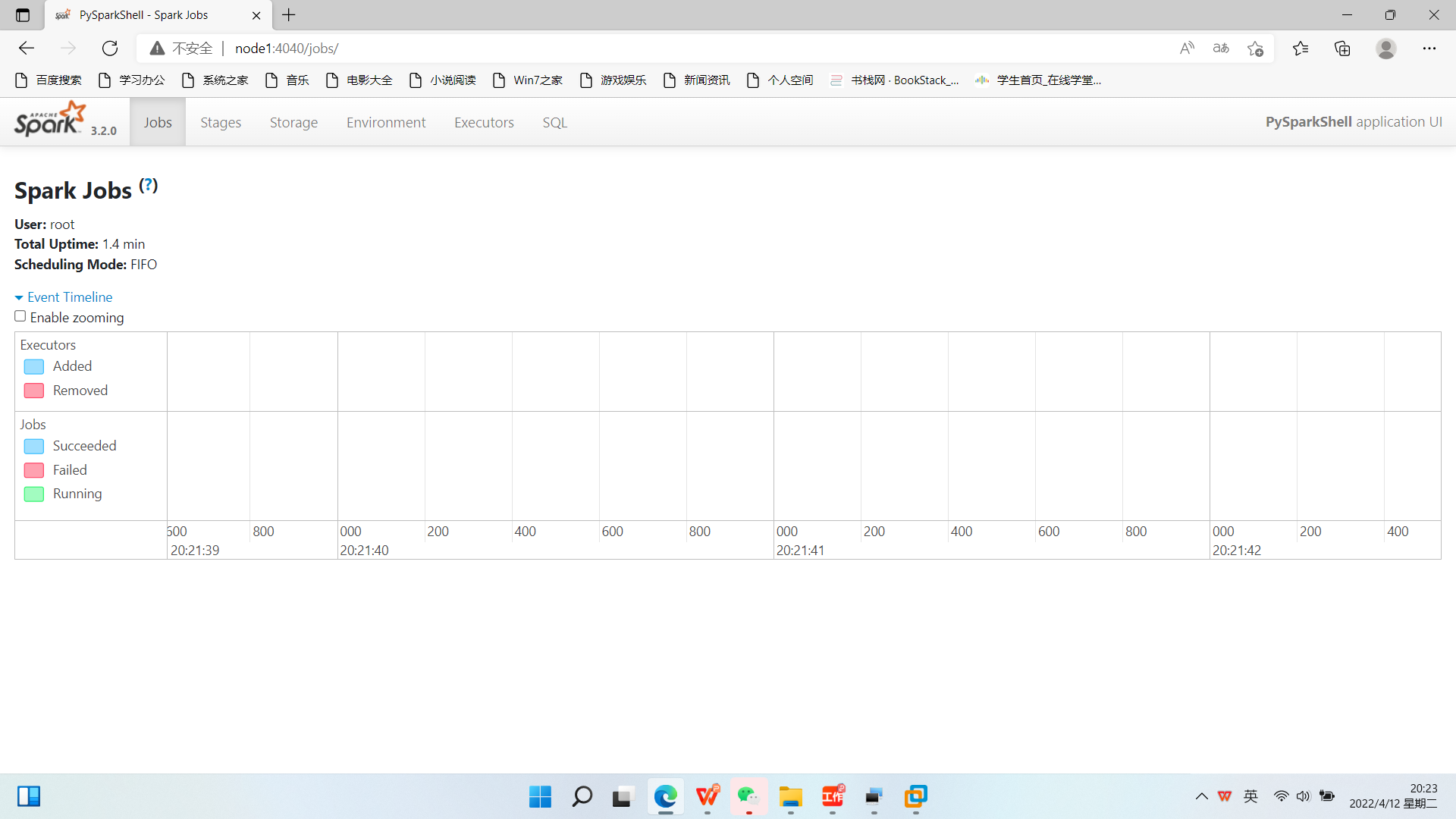
\12. 进入WEB界面(node1:4040/)
\13. 退出
1 | conda deactivate |
*六、Spark-Standalone模式*
\1. 在node2、node3上安装Python(Anaconda)
出现base表明安装完成
\2. 将node1上的profile和./bashrc分发给node2、node3
#分发.bashrc
1 | scp ~/.bashrc root@node2:~/ |
#分发profile
1 | scp /etc/profile/ root@node2:/etc/ |
\3. 创建虚拟环境pyspark基于python3.8
1 | conda create -n pyspark python=3.8 |
\4. 切换到虚拟环境
1 | conda activate pyspark |

\5. 在虚拟环境内安装包
1 | pip install pyhive pyspark jieba -i https://pypi.tuna.tsinghua.edu.cn/simple |
\6. 修改配置文件
1 | cd /export/server/spark/conf |
-配置workers
1 | mv workers.template workers |
1 | vim workers |
# 将里面的localhost删除, 追加
1 | node1 |
-配置spark-env.sh
1 | mv spark-env.sh.template spark-env.sh |
1 | vim spark-env.sh |
在底部追加如下内容
1 | ## 设置JAVA安装目录 JAVA_HOME=/export/server/jdk |
\7. 在HDFS上创建程序运行历史记录存放的文件夹:
1 | hadoop fs -mkdir /sparklog |
-配置spark-defaults.conf.template
1 | mv spark-defaults.conf.template spark-defaults.conf |
1 | vim spark-defaults.conf |
# 修改内容, 追加如下内容
1 | # 开启spark的日期记录功能 spark.eventLog.enabled true |
-配置log4j.properties
1 | mv log4j.properties.template log4j.properties |
1 | vim log4j.properties |

\8. 将node1的spark分发到node2、node3
1 | cd /export/server/ |
\9. 在node2和node3上做软连接
1 | ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/spark |
\10. 重新加载环境变量
1 | source /etc/profile |
\11. 启动历史服务器
1 | cd /export/server/spark/sbin |
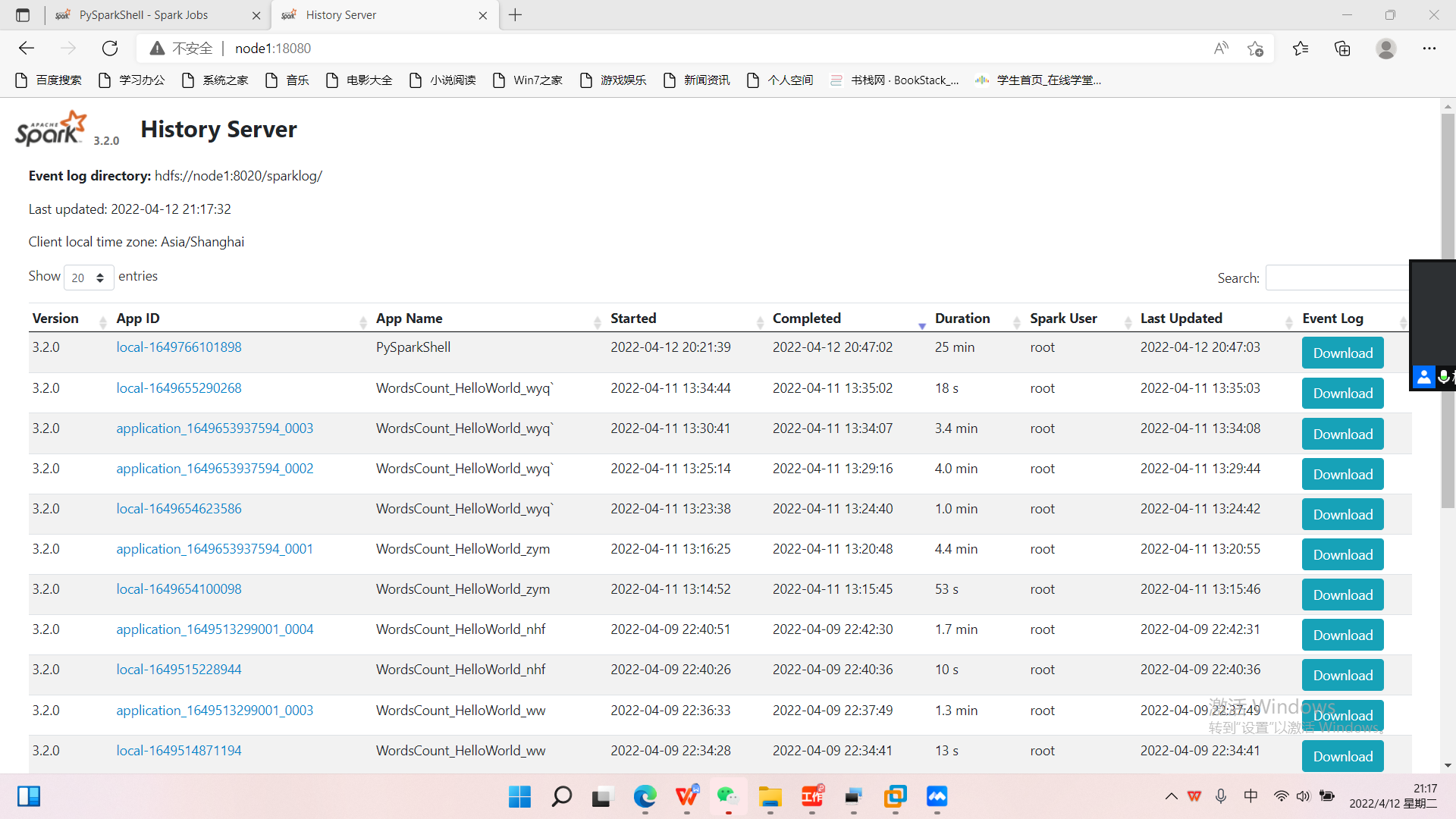
\12. 访问WebUI界面(http://node1:18080/)
\13. 启动Spark的Master和Worker
# 启动全部master和worker sbin/start-all.sh
# 或者可以一个个启动:
# 启动当前机器的master
1 | sbin/start-master.sh |
# 启动当前机器的worker
1 | sbin/start-worker.sh |
# 停止全部
1 | sbin/stop-all.sh |
# 停止当前机器的master
1 | sbin/stop-master.sh |
# 停止当前机器的worker
1 | sbin/stop-worker.sh |
\14. 访问WebUI界面(http://node1:8080/)