三、*生产者API*
一个正常的生产逻辑需要具备以下几个步骤
(1)配置生产者客户端参数及创建相应的生产者实例
(2)构建待发送的消息
(3)发送消息
(4)关闭生产者实例
\1. 新建Maven项目,配置pom.xml
\2. 新建ProducerDemo类,ProducerCallbackDemo类
\3. 生产者原理
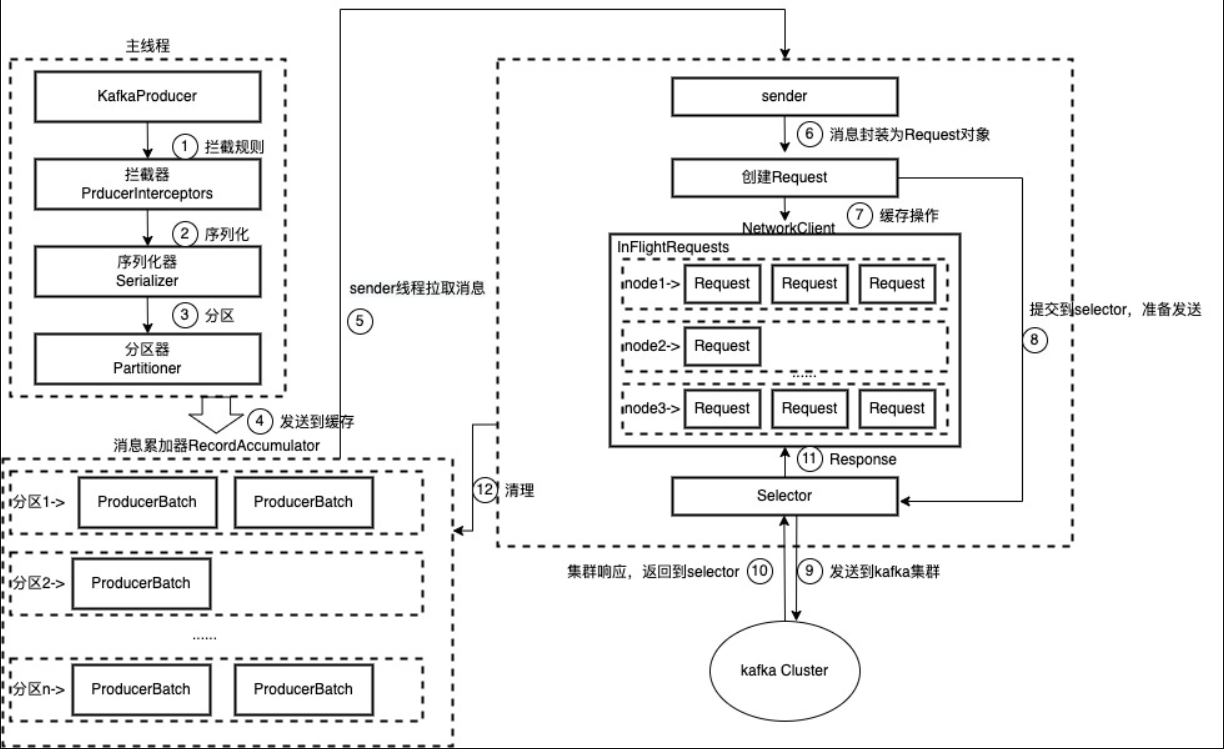
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender(发送线程)。在主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
RecordAccumulator 主要用来缓存消息以便Sender线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
主线程中发送过来的消息都会被追加到RecordAccumulator的某个双端队列(Deque)中,在RecordAccumulator的内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即Deque。消息写入缓存时,追加到双端队列的尾部;Sender读取消息时,从双端队列的头部读取。
消息在网络上都是以字节(Byte)的形式传输的,在发送之前需要创建一块内存区域来保存对应的消息。在Kafka生产者客户端中,通过java.io.ByteBuffer实现消息内存的创建和释放。不过频繁的创建和释放是比较消耗资源的,在RecordAccumulator的内部还有一个BufferPool,它主要用来实现ByteBuffer的复用,以实现缓存的高效利用。
\4. ack应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,
所以没必要等 ISR 中的 follower 全部接收成功。
所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks = 0:生产者只负责发消息,不管Leader 和Follower 是否完成落盘就会发送ack 。这样能够最大降低延迟,但当Leader还未落盘时发生故障就会造成数据丢失。
acks = 1:Leader将数据落盘后,不管Follower 是否落盘就会发送ack 。这样可以保证Leader节点内有一份数据,但当Follower还未同步时Leader发生故障就会造成数据丢失。
acks = -1(all):生产者等待Leader 和ISR 集合内的所有Follower 都完成同步才会发送ack 。但当Follower 同步完之后,broker发送ack之前,Leader发生故障时,此时会重新从ISR内选举一个新的Leader,此时由于生产者没收到ack,于是生产者会重新发消息给新的Leader,此时就会造成数据重复。
四、*消费者API*
一个正常的消费逻辑需要具备以下几个步骤:
(1)配置消费者客户端参数
(2)创建相应的消费者实例;
(3)订阅主题;
(4)拉取消息并消费;
(5)提交消费位移 offset;
(6)关闭消费者实例。
\1. subscribe 有如下重载方法:
public void subscribe(Collection
public void subscribe(Collection
public void subscribe(Pattern pattern, ConsumerRebalanceListener listener)
public void subscribe(Pattern pattern)
\2. 指定集合方式订阅主题
consumer.subscribe(Arrays.asList(topic1));
consumer subscribe(Arrays.asList(topic2))
\3. 正则方式订阅主题
如果消费者采用的是正则表达式的方式(subscribe(Pattern))订阅, 在之后的过程中,如果有人又创建了新的主题,并且主题名字与正表达式相匹配,那么这个消费者就可以消费到新添加的主题中的消息。如果应用程序需要消费多个主题,并且可以处理不同的类型,那么这种订阅方式就很有效。
\4. assign 订阅主题
这个方法只接受参数 partitions,用来指定需要订阅的分区集合
\5. subscribe 与 assign 的区别
(1)通过 subscribe()方法订阅主题具有消费者自动再均衡功能 ;
在多个消费者的情况下可以根据分区分配策略来自动分配各个消费者与分区的关系。
当消费组的消费者增加或减少时,分区分配关系会自动调整,以实现消费负载均衡及故障自动转移。
(2)assign() 方法订阅分区时,是不具备消费者自动均衡的功能的;
其实这一点从 assign()方法参数可以看出端倪,两种类型 subscribe()都有 ConsumerRebalanceListener 类型参数的方法,而 assign()方法却没有。
\6. 消息的消费模式
Kafka 中的消费是基于拉取模式的。消息的消费一般有两种模式:推送模式和拉取模式。
推模式是服务端主动将消息推送给消费者,而拉模式是消费者主动向服务端发起请求来拉取消息
Kafka 中的消息消费是一个不断轮询的过程,消费者所要做的就是重复地调用 poll() 方法, poll() 方法返回的是所订阅的主题(分区)上的一组消息。
\7. 指定位移消费
seek() 方法:从特定的位移处开始拉取消息
\8. 再均衡监听器
一个消费组中,一旦有消费者的增减发生,会触发消费者组的 rebalance 再均衡;
如果 A 消费者消费掉的一批消息还没来得及提交 offset, 而它所负责的分区在 rebalance 中转移给了 B 消费者,则有可能发生数据的重复消费处理。此情形下,可以通过再均衡监听器做一定程度的补救;
\9. 自动位移提交
Kafka 消费的编程逻辑中位移提交是一大难点,自动提交消费位移的方式非常简便,它免去了复杂的位移提交逻辑,让编码更简洁。但随之而来的是重复消费和消息丢失的问题。
(1)重复消费
假设刚刚提交完一次消费位移,然后拉取一批消息进行消费,在下一次自动提交消费位移之前,消费者崩溃了,那么又得从上一次位移提交的地方重新开始消费,这样便发生了重复消费的现象(对于再均衡的情况同样适用)。我们可以通过减小位移提交的时间间隔来减小重复消息的窗口大小,但这样并不能避免重复消费的发送,而且也会使位移提交更加频繁。
(2)丢失消息
拉取线程不断地拉取消息并存入本地缓存, 比如在 BlockingQueue 中, 另一个处理线程从缓存中读取消息并进行相应的逻辑处理
\10. 新建ConsumerDemo,ConsumerDemo1,ConsumerTask,ConsumerDemo2,ConsumerSeekOffset类
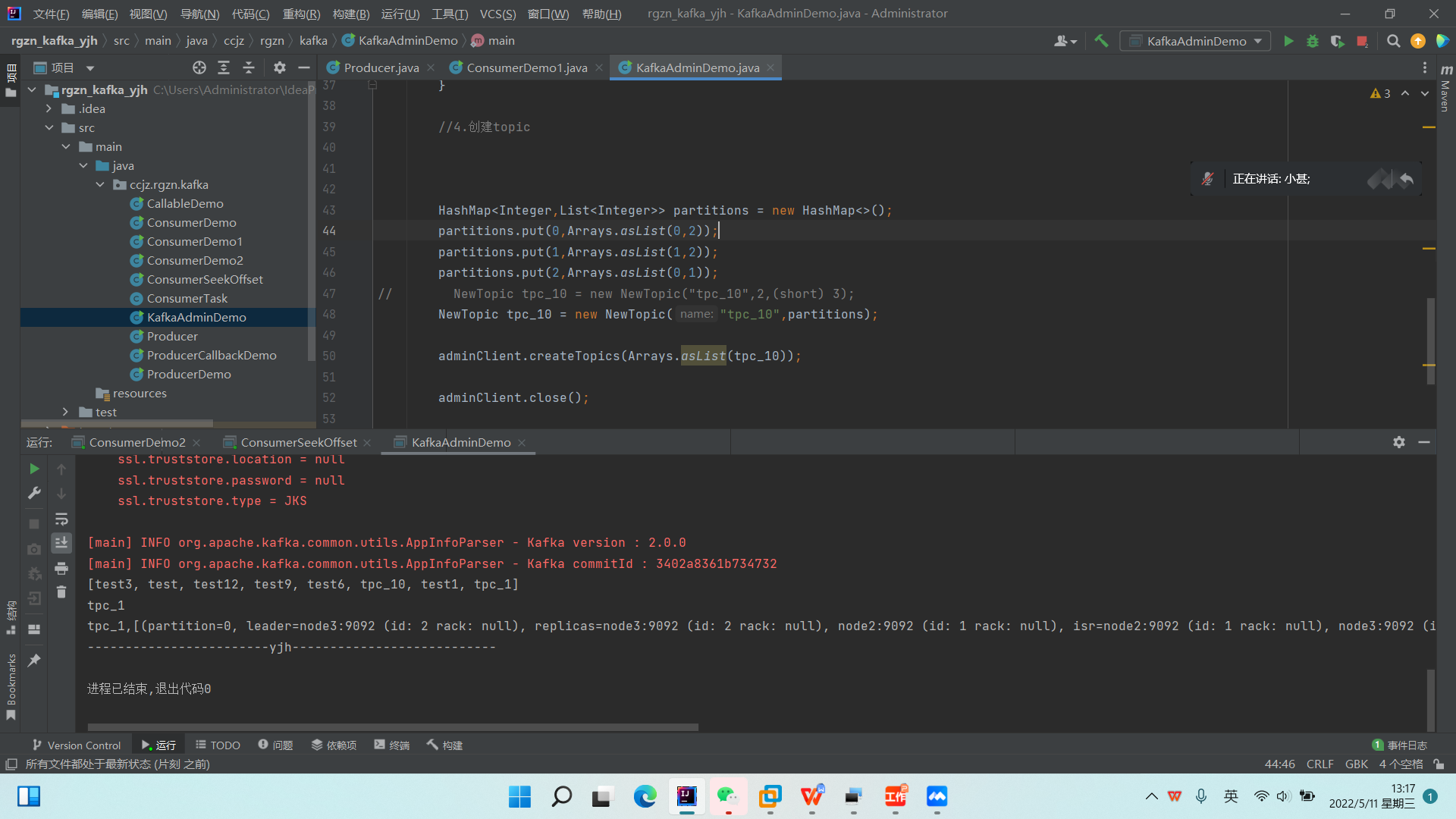
五、*Topic管理API*
KafkaAdminClient 不仅可以用来管理 broker、配置和 ACL (Access Control List),还可用来管理主题)它提供了以下方法:

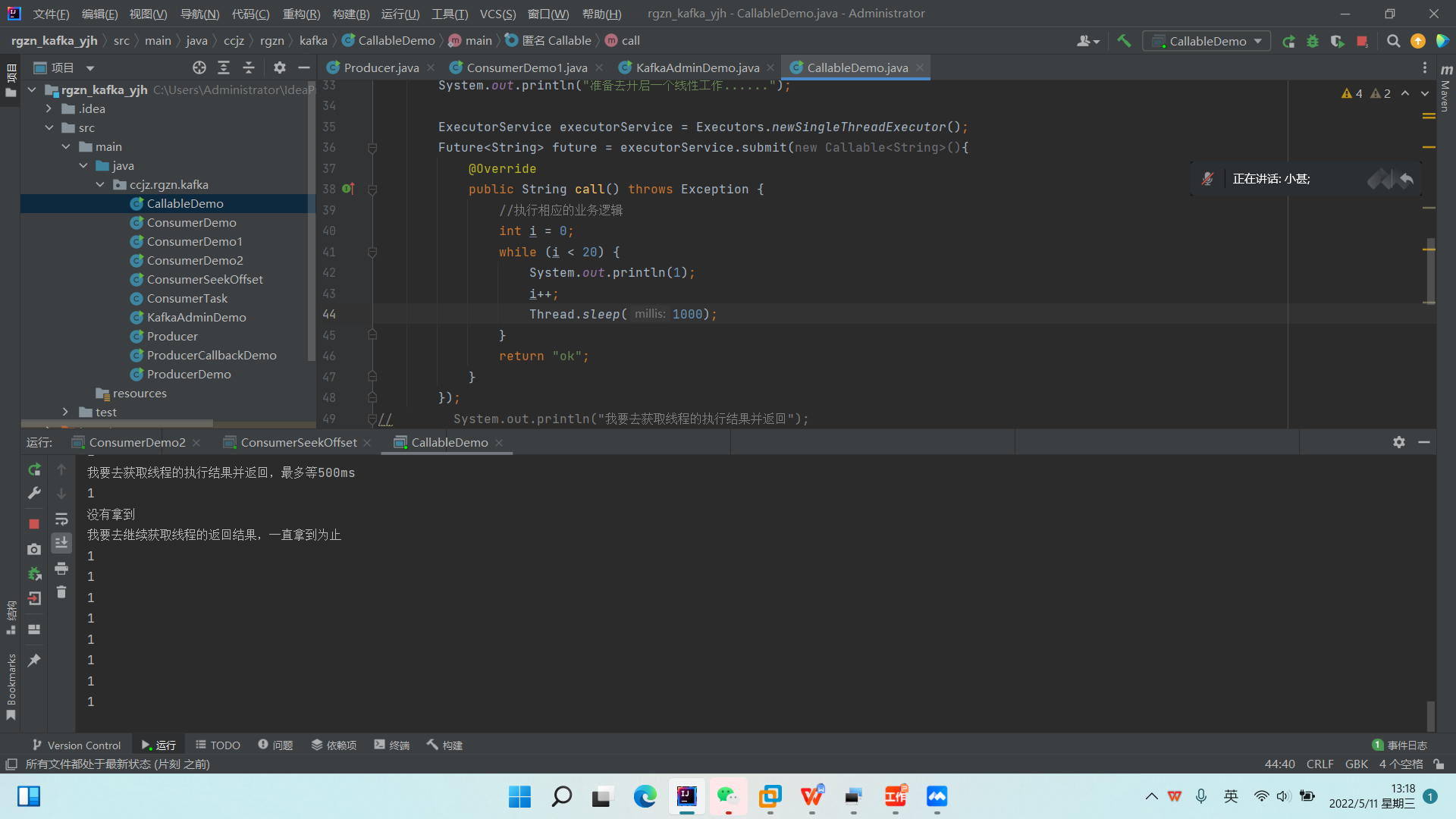
\1. 新建KafkAdminDemo,CallableDemo类